Monday B: Running JEDI¶
Part 1: Simulating Observations like the JCSDA Near-Real-Time (NRT) Application¶
- In this activity you will:
Create simulated observations similar to those highlighted on JCSDA’s Near Real-Time (NRT) Observation Modeling web site
Acquaint yourself with the rich variety of observation operators now available in UFO
The comparison between observations and forecasts is an essential component of any data assimilation (DA) system and is critical for accurate Earth System Prediction. It is common practice to do this comparison in observation space. In JEDI, this is done by the Unified Forward Operator (UFO). Thus, the principle job of UFO is to start from a model background state and to then simulate what that state would look like from the perspective of different observational instruments and measurements.
In the data assimilation literature, this procedure is often represented by the expression \(h({\bf x})\). Here \({\bf x}\) represents prognostic variables on the model grid, typically obtained from a forecast, and \(H\) represents the observation operator that generates simulated observations from that model state. The sophistication of observation operators varies widely, from in situ measurements where it may just involve interpolation and possibly a change of variables (e.g. radiosondes), to remote sensing measurements that require physical modeling to produce a meaningful result (e.g. radiance, GNSSRO).
So, in this activity, we will be running an application called \(h({\bf x})\), which is often denoted in program and function names as Hofx. This in turn will highlight the capabilities of JEDI’s Unified Forward Operator (UFO).
The goal is to create plots comparable to JCSDA’s Near Real-Time (NRT) Observation Modeling web site. This site regularly ingests observation data for the complete set of operational instruments at NOAA. And, it compares these observations to forecasts made through NOAA’s operational Global Forecasting System (FV3-GFS) and NASA’s Goddard Earth Observing System (FV3-GEOS).
But there is a caveat. The NRT web site regularly simulates millions of observations using model backgrounds with operational resolution - and it does this every six hours! That requires substantial high-performance computing (HPC) resources. We want to mimic this procedure in a way that can be run quickly on our AWS nodes. So, the model background you will use will be at a much lower horizontal resolution (c48, corresponding to about 14 thousand points in latitude and longitude) than the NRT website (GFS operational resolution of c768, corresponding to about 3.5 million points).
Step 1.1: Setup¶
Now that you have finished the first activity, you have built and tested fv3-bundle and you’re ready to use it. So, if you are not there already, log in to your AWS node and re-enter the container:
singularity shell -e jedi-gnu-openmpi-dev_latest.sif
Now, the description in the previous section gives us a good idea of what we need to run \(h({\bf x})\). First, we need \({\bf x}\) - the model state. In this activity we will use background states from the FV3-GFS model with a resolution of c48, as mentioned above.
Next, we need observations to compare our forecast to. Example observations available in the data set we will download include (see the NRT website for an explanation of acronyms):
Aircraft
Sonde
Satwinds
Scatwinds
Vadwind
Windprof
SST
Ship
Surface
cris-npp
cris-n20
airs-aqua
gome-metopa
gome-metopb
sbuv2-n19
amsua-aqua
amsua-n15
Amsua-n18
amsua-n19
amsua-metopa
amsua-metopb
amsua-metopc
iasi-metopa
iasi-metopb
seviri-m08
seviri-m11
mhs-metopa
mhs-metopb
mhs-metopc
mhs-n19
ssmis-f17
ssmis-f18
atms-n20
The script to download these background and observation files is in fv3-bundle. But, before we run it, let’s create a new directory where we will run our applications and then copy over the scripts and configuration files we’ll be using to run our application:
mkdir -p ~/jedi/tutorials
cp -r ~/jedi/fv3-bundle/tutorials/Hofx ~/jedi/tutorials
cd ~/jedi/tutorials/Hofx
chmod a+x run.bash
We’ll call ~/jedi/tutorials/Hofx the run directory.
Now we are ready to run the script to obtain the input data (enter this from the run directory):
./get_input.bash
You only need to run this once. It will retrieve the background and observation files from a remote server and place them in a directory called input.
We will also need to install some python tools for viewing the results of our applications after we run them. These will be used in other activities as well, throughout the Academy. Be sure to run these commands inside the container to ensure you have a consistent python environment:
cd ~/jedi
git clone https://github.com/jcsda-internal/fv3-jedi-tools
cd fv3-jedi-tools
/usr/local/miniconda3/bin/pip install --user -e .
export PATH=$HOME/.local/bin:$PATH
You may have already noticed that there is another directory in your run directory called config. Take a look. Here are a different type of input files, including configuration (yaml) files that specify the parameters for the JEDI applications we’ll run and fortran namelist files that specify configuration details specific to the FV3-GFS model.
Step 1.2: Run the Hofx application¶
There is a file in the run directory called run.bash. Take a look. This is what we will be using to run our Hofx application.
Before running a JEDI application, it’s always good to just make sure we disable the stack size limits, as we did when we ran the ctests in the first activity:
ulimit -s unlimited
ulimit -v unlimited
When you are ready, try it out:
cd ~/jedi/tutorials/Hofx
./run.bash
If you omit the arguments, the script just gives you a list of instruments that are highlighted in this activity. For Step 1.2 we will focus on radiance data from the AMSU-A instrument on the NOAA-19 satellite:
./run.bash Amsua_n19
Skim the text output as it is flowing by. Can you spot where the quality control (QC) on the observations is being applied?
Step 1.3: View the Simulated Observations¶
You’ll find the graphical output from Step 1.2 in the output/plots/Amsua_n19 directory. If you are using the JupyterLab interface, you can just navigate to this directory and select the image files to view them.
You can start with the temperature observation, brightness_temperature_12_ObsValue.png, which should look something like what is shown on the JCSDA NRT web site.
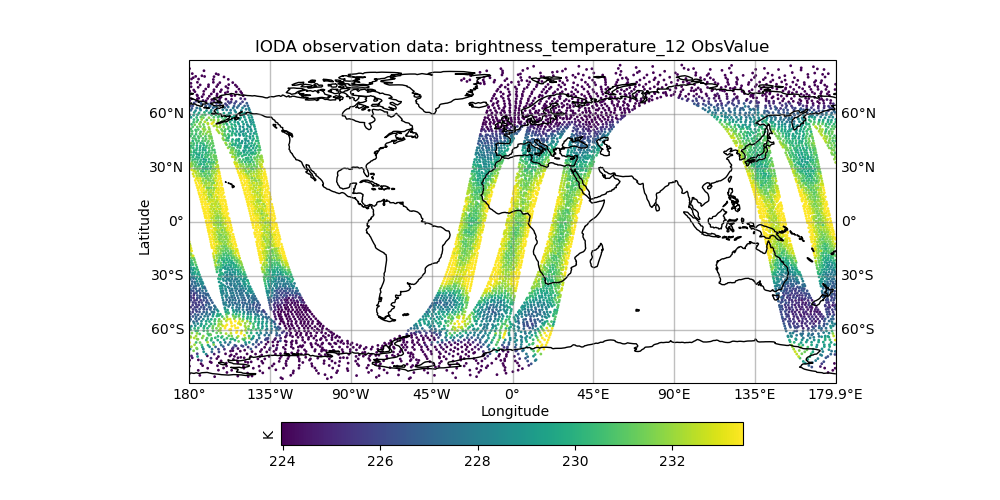
This shows temperature measurements over a 6-hour period. Each band of points corresponds to an orbit of the spacecraft.
Note
If you are accessing your AWS node through ssh rather than JupyterLab, then you can use the linux utility feh to view the png files from within the container, e.g. feh brightness_temperature_12_ObsValue.png. You may have to set your DISPLAY environment variable inside the container to match what it is outside the container. Consult a JEDI master for further information.
Now look at some of the other fields. The files marked with ObsValue correspond to the observations and the files marked with hofx represent the simulated observations computed by means of the \(h({\bf x})\) operation described above. This forward operator relies on JCSDA’s Community Radiative Transfer Model (CRTM) to predict what this instrument would see for that model background state.
The files marked omb represent the difference between the two: observations minus background. In data assimilation this is often referred to as the innovation and it plays a critical role in the forecasting process; it contains newly available information from the latest observations that can be used to improve the next forecast. To see the innovation for this instrument over this time period, view the file brightness_temperature_12_omb.png.
If you are curious, you can find the application output in the directory called output/hofx. There you’ll see 12 files generated, one for each of the 12 MPI tasks. This is the data from which the plots are created. The output filenames include information about the application (hofx3d), the model and resolution of the background (gfs_c48), the file format (ncdiag), the instrument (amsua), and the time stamp.
Step 1.4: Explore¶
The main objective here is to return to Steps 1.2 and 1.3 and repeat for different observation types. Try running another observation type from the list returned by run.bash and look at the results in the output/plots directory. A few suggestions: look at how the aircraft observations trace popular flight routes; look at the mean vertical temperature and wind profiles as determined from radiosondes; discover what observational quantities are derived from Global Navigation Satellite System radio occultation measurements (GNSSRO); revel in the 22 wavelength channels of the Advanced Technology Microwave Sounder (ATMS). For more information on any of these instruments, consult JCSDA’s NRT Observation Modeling web site.
(optional) Attentive padawans may notice an unused configuration file in the config directory called Medley_gfs.hofx3d.jedi.yaml. If you time after finishing Part 2 of this activity, you may wish to return to this step and try running this yourself, guided by the run.bash script. This runs a large number of different observation types so it takes much longer to run. This is included in the tutorial merely to give you the flavor of what is involved in creating the NRT site. This generates plots for over 40 instruments every six hours, using higher-resolution model backgrounds that have more than 250 times more horizontal points than what we are running here. The GEOS-NRT site goes a step further in terms of computational resources - displaying continuous 4D \(h({\bf x})\) calculations.
Part 2: Run DA Applications with FV3-GFS¶
- In this activity you will:
Run 3D EnVar and 4D EnVar applications with FV3-GFS
View an increment
In Part 1 we made use of FV3-GFS background files but we did not actually run the FV3-GFS model. In this part of the activity we will.
More specifically, we will be running a low-resolution version of the FV3 model as implemented in NOAA’s Global Forecast System, FV3-GFS. We’ll run both 3D and 4D ensemble variational applications (3D EnVar, 4D EnVar) and compare the increments that each produces.
Step 2.1: Run 3D EnVar and 4D EnVar Applications¶
As in Part 1, it’s most convenient if we create a separate directory to run our applications and then copy over the files we need to get started:
mkdir -p ~/jedi/tutorials
cp -r ~/jedi/fv3-bundle/tutorials/runjedi ~/jedi/tutorials
cd ~/jedi/tutorials/runjedi
chmod a+x run.bash
So, our run directory is now ~/jedi/tutorials/runjedi.
Take a look at the files you just copied over. The run script defines a workflow that is needed to run a variational data assimilation application with FV3-JEDI and the B-Matrix Unstructured Mesh Package (BUMP). First BUMP is used to compute the correlation statistics and localization for the background error covariance matrix (B-Matrix). Then the variational application is run, and a separate application computes the increment. Each application runs with at least 6 MPI tasks (the minimum for fv3) and requires only one argument, namely a (yaml) configuration file). A log file is also specified for saving the text output.
The config directory contains jedi configuration files in yaml format that govern the execution of the application, including the specification of input data files, control flags, and parameter values. If you look inside, you’ll see references to where the input data files are. For example, the ~/jedi/build/fv3-jedi/test/Data/fv3files directory contains namelist and other configuration files for the FV3 model and the ~/jedi/build/fv3-jedi/test/Data/inputs/gfs_c12 directory contains model backgrounds and ensemble states that are used to define the grid, initialize forecasts, and compute the B-Matrix. The c12 refers to the horizontal resolution, signifying 12 by 12 grid points on each of the 6 faces of the cubed sphere grid, or 864 horizontal grid points total. This is, of course, much lower resolution than operational forecasts but it is sufficient to run efficiently for a tutorial!
If you peruse the config files further, you may see references to the ~/jedi/build/fv3-jedi/test/Data/obs directory, which contains links to the observation files that are being assimilated. Another source of input data is the ~/jedi/build/fv3-jedi/test/Data/crtm directory, which contains coefficients for JCSDA’s Community Radiative Transfer Model (CRTM) that are used to compute simulated satellite radiance observations from model states (i..e. observation operators).
We again encourage you to explore these various directories to get a feel for how the input to jedi applications is provided.
Now let’s run a 3D variational data assimilation application that uses an ensemble-based background error covariance matrix:
./run.bash 3denvar
Before we view the results, let’s also run the 4D equivalent:
./run.bash 4denvar
The objective of the run.bash script is to produce an increment. In DA terminology, this represents a change to the background state that will bring it in closer agreement with the observations. This can be done either by minimizing a cost function at a fixed model time (3denvar) or by taking into account the dynamical evolution of the model state over the assimilation time interval (4denvar). The latter is expected to be more accurate, but also more computationally intensive.
The output of each of these experiments can now be found in the run-3denvar and run-4denvar directories respectively. A detailed investigation of this output is beyond the scope of this activity (we will be exploring this more tomorrow) but you may wish to take a few moments to survey the types of output files that are produced.
Step 2.2: View the Increment¶
As mentioned above, the last application in the run.bash script generates an increment that can be plotted. This is rendered as a netcdf file. To plot the increment, we can use the fv3-jedi-tools package we installed in Step 1.1:
fv3jeditools.x 2018-04-15T00:00:00 config/3denvar-plot.yaml
After running this, navigate to the run-3denvar/increment directory with the JupyterLab navigation tool and double-click on the image file, 3denvar.latlon.20180415_000000z_T_layer-50.png (again, if you are not using the JupyterLab interface, you can use feh to view the images: see note above). It should look something like this:
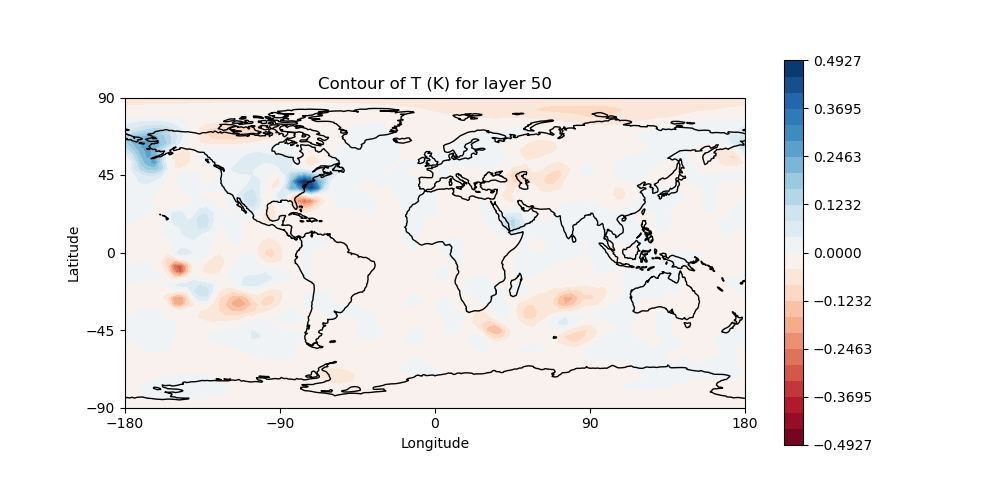
This is the change to the model temperature that will bring the forecast in closer agreement with observations, as determined by the 3denvar algorithm.
Now we invite you to explore. To view different fields and levels, you can edit the plot configuration file config/3denvar-plot.yaml. The list of field names to choose from is the same list that is specified near the bottom of the 3denvar-increment.yaml configuration file in the config directory: ua, va, T, ps, sphum, ice_wat, liq_wat, and o3mr (you can find the same list in the 3denvar.yaml file under “analysis variables”). Available levels range from 1 (top of the atmosphere) to 64 (ground level). In each case the program will tell you the name of the image file it is creating.
When you are finished exploring the 3denvar increment, move to the run-4denvar/increment directory and repeat the process there (note that the configuration file has a different name). The list of available variables and levels is the same, so you can compare. Try opening up the same field and level in for 3denvar and 4denvar and toggle between them by selecting each JupyterLab tab in turn.
Step 2.3: Change the Configuration¶
If you have time, you might wish to edit the configuration files in the config directory and see how that effects the resulting increments. If you do not have time, don’t worry - we will be doing more of this sort of thing in the activities tomorrow.
Here are a few possible activities - we encourage you to come up with your own:
change the variable list in one or more of the observations that are assimilated. For example, you can remove
eastward_windandnorthward_windfrom the aircraft and/or radiosonde observations, leaving only temperature.remove one of the observation types entirely, such as aircraft or GNSSRO refractivity measurements (hint: you may wish to review the basic yaml syntax to see how components of a particular yaml item are defined).
change the localization length scales for bump (hint:
rhandrvcorrespond to horizonal and vertical length scales respectively, in units of meters)
After each change remember to run the run.bash script again to generate new output.