Practical 2: Data Assimilation with JEDI-FV3¶
- Learning Goals:
How to download and run/enter a JEDI application container
Introduction to the JEDI source code and directory structure
How to run a JEDI DA application inside the container
How to view an increment
Overview¶
In this practical we will be running a low-resolution version of the FV3 model as implemented in NOAA’s Global Forecast System, FV3-GFS. We’ll run both 3D and 4D ensemble variational applications (3DEnVar, 4DEnVar) and compare the increments that each produces.
JEDI packages are organized into bundles. A bundle includes a collection of GitHub repositories needed to build and run JEDI with a particular model. In this practical, as in the last, we will be working with``fv3-bundle``.
All JEDI bundles include the base JEDI component of the Object Oriented Prediction System (OOPS), the Interface for Observational Data Access (IODA), the Unified Forward Operator (UFO) and the System-Agnostic Background Error Representation (SABER). The interface between FV3-based models and JEDI is implemented through the FV3-JEDI code repository.
Most bundles will also include additional repositories that provide the forecast model and the physics packages or software infrastructure that supports it. Some bundles may also include supplementary repositories that support different observation types, such as an alternative radiative transfer model or tools for working with radio occultation measurements from global navigation satellite systems.
Which JEDI bundle you build depends on which atmospheric or oceanic model you plan to work with.
Step 1: Enter the JEDI Container (Skip if you are there already)¶
If you exited the container at the end of the last practical you can re-enter it at any time with the command:
singularity shell -e jedi-tutorial_latest.sif
And, when you start a fresh container session, it’s good practice to make sure JEDI has enough memory, as we did in the first practical. Let’s also specify one OpenMP thread:
ulimit -s unlimited
ulimit -v unlimited
export OMP_NUM_THREADS=1
Step 2: Run a JEDI DA Application¶
As we saw in the first practical, the container contains everything you need to run a Data Assimilation (DA) application. In addition to the executables and test data files in /opt/jedi/build, there are also various configuration files in the /opt/jedi/fv3-bundle/tutorials directory. To proceed, let’s copy over the configuration files we need:
mkdir -p $HOME/jedi/tutorials/runjedi
cp -r /opt/jedi/fv3-bundle/tutorials/runjedi/config $HOME/jedi/tutorials/runjedi
cd $HOME/jedi/tutorials/runjedi
export jedibin=/opt/jedi/build/bin
The last command sets the environment variable jedibin to point to the directory that contains the executable applications for fv3-bundle.
The conf directory contains jedi configuration files in yaml format that govern the execution of the application, including the specification of input data files, control flags, and parameter values. If you look inside, you’ll see references to where the input data files are. For example, the /jedi/build/fv3-jedi/test/Data/fv3files directory contains namelist and other configuration files for the FV3 model and the /jedi/build/fv3-jedi/test/Data/inputs/gfs_c12 directory contains model backgrounds and ensemble states that are used to define the grid, initialize forecasts, and compute the B-Matrix. The c12 refers to the horizontal resolution, signifying 12 by 12 grid points on each of the 6 faces of the cubed sphere grid, or 864 horizontal grid points total. This is, of course, much lower resolution than operational forecasts but it is sufficient to run efficiently for a practical!
If you peruse the config files further, you may see references to the /jedi/build/fv3-jedi/test/Data/obs directory, which contains links to the observation files that are being assimilated. Another source of input data is the /jedi/build/fv3-jedi/test/Data/crtm directory, which contains coefficients for JCSDA’s Community Radiative Transfer Model (CRTM) that are used to compute simulated satellite radiance observations from model states (i..e. observation operators).
We again encourage you to explore these various directories to get a feel for how the input to jedi applications is provided.
Now let’s run a 3D ensemble variational application: 3denvar. Data assimilation involves a background error covariance model. The variational assimilation system we are running today uses a pure ensemble error covariance model but it requires localization in order to give a sensible analysis. The first step we need to take is to generate this localization model.
# Create a directory to hold the localization model files
mkdir -p bump
# Run the application to generate the localization model
mpirun -np 6 $jedibin/fv3jedi_parameters.x config/bumpparameters_nicas_gfs.yaml
The localization model is fixed and does not even depend on the time for which the analysis is being run. So the above step is taken only once, even if changing the configuration for the variational assimilation.
Now we can run the data assimilation system and produce the analysis.
# Create directory to hold the resulting analysis
mkdir -p run-3denvar/analysis
# Create directory to hold resulting hofx data
mkdir -p run-3denvar/hofx
# Create directory to hold resulting log files
mkdir -p Logs
# Run the variational data assimilation application
mpirun -np 6 $jedibin/fv3jedi_var.x config/3denvar.yaml Logs/3denvar.log
Now note that the config directory also contains a corresponding file for a 4D ensemble variational DA application: 4denvar.yaml. To run this application, repeat the steps above, replacing 3denvar everywhere with 4denvar. Note that you do not have to run the bump localization model again. Be sure to create new run-4denvar directories as shown above so you don’t overwrite your previous results. Important: you will need to run the 4denvar application with 18 mpi tasks instead of 6.
The output of each of these experiments can now be found in the run-3denvar and run-4denvar directories respectively. A detailed investigation of this output is beyond the scope of this practical but you may wish to take a few moments to survey the types of output files that are produced. The simulated observations are in the hofx directory and the analysis directories contain the application’s “best guess” for the state of the atmosphere, based on a combination of the model background state and the observations.
Step 3: Compute and View the Increments¶
In DA terminology, an increment represents a change to the background state that will bring it in closer agreement with the observations. This is obtained by subtracting the background from the analysis. For the 3devar application, this can be done by running the diffstates application as follows:
# Create directory to hold the increment
mkdir -p run-3denvar/increment
# compute the increment
mpirun -np 6 $jedibin/fv3jedi_diffstates.x config/3denvar-increment.yaml Logs/3denvar-increment.log
The resulting increment is rendered as a netcdf file. To create an image for viewing, go to the 3denvar increment directory and run this program:
cd run-3denvar/increment
fv3jedi_plot_field.x --inputfile=3denvar.latlon.20180415_000000z.nc4 --fieldname=T --layer=50
Here we have specified the input file, the field we want to see, in this case temperature, and the vertical layer. You can view the resulting image file, 3denvar.latlon.20180415_000000z_T_layer-50.png, by clicking on it as we did in the first practical.
You should now be able to see the temperature increment and it should look something like this:
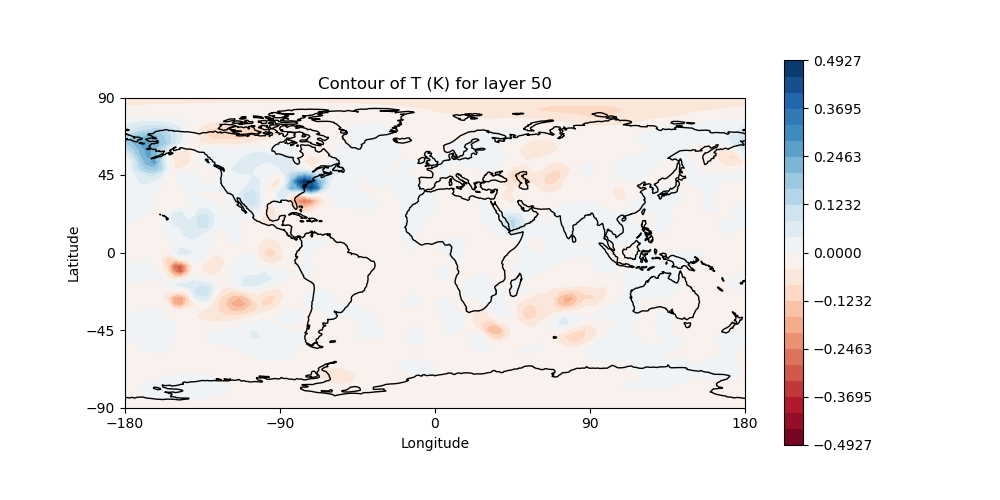
This is the change to the model temperature that will bring the forecast in closer agreement with observations, as determined by the 3denvar algorithm.
Now we invite you to explore. Try viewing the surface pressure increment as follows (note this is a 2D field so there is no need to specify a layer).
fv3jedi_plot_field.x --inputfile=3denvar.latlon.20180415_000000z.nc4 --fieldname=ps
feh 3denvar.latlon.20180415_000000z_ps.png
Feel free to view other fields and levels. The list of field names to choose from is the same list that is specified near the bottom of the 3denvar-increment.yaml configuration file in the config directory: ua, va, T, ps, sphum, ice_wat, liq_wat, and o3mr. Available levels range from 1 (top of the atmosphere) to 64 (ground level). In each case the program will tell you the name of the image file it is creating.
When you are finished exploring the 3denvar increment, repeat the process for the 4denvar. The list of available variables and levels is the same, so you can compare.
Step 4: Review of YAML files¶
Programmers and computers typically store data as complex “objects” (structures and classes). In a computer’s memory, these objects may have very complicated storage involving pointers, references, dictionaries, and similar constructs. However, when we need to store these complex structures to a disk or send them across a network, we have to translate these complex structures into a series of bytes (a.k.a. we serialize an object into a byte stream).
There are lots of ways of doing this. However, JEDI wanted to employ a consistent, well-documented format that is easy for people to edit and for machines to read. So, we chose to use the YAML Ain’t Markup Language (YAML) format to store the configuration data for the JEDI project.
YAML was developed in 2001 and has been implemented for use with several programming languages.
Let’s take a look at a YAML file for a brief overview.
---
# Comments are indicated with the '#' symbol.
name: "Your name here" # A string
a-boolean-value: true
an-integer-value: 3
pi: 3.14159
list-of-some-jedi-components:
- saber
- oops
- ioda
- ufo
dictionary-of-places-to-explore-in-a-staycation:
- local-park:
scenic: true
features:
- "Running trails"
- Trees
- "Duck pond"
- aquarium:
types-of-animals:
- jellyfish
- turtles
- fish
free: false
mask: true
# TODO: Explore this area and add more details.
The file starts with three dashes. These dashes indicate the start of a new YAML document. YAML supports multiple documents, and compliant parsers will recognize each set of dashes as the beginning of a new one.
Comments are started with a space and a hashtag (” #”) and extend to the end of the line.
Next, we see the construct that makes up most of a typical YAML document: a key-value pair. “name” is a key that points to a string value: “Your name here”. YAML allows for several types of values: strings, integers, floating-point numbers, boolean values and dates are all acceptable.
Strings can optionally be enclosed in quotes. Quotes include both single and double quotes.
You can also add in arrays / lists. Each element in a list is denoted by an opening dash.
YAML elements can also be nested. This lets you emulate a group / folder structure. Nesting is accomplished by adding levels of spaces (no tabs allowed).
See this link for more examples.
Step 5: Change the Configuration¶
Now, if you have time, armed with your new understanding of yaml files, try editing the configuration files in the config directory and see how that effects the resulting increments.
The JupyterLab interface comes with a built-in yaml editor so you can just click on the file to edit it.
If you make a change and want to verify that the yaml syntax is correct, then you can copy and paste your text into one of many online yaml validators to check (google yaml validator for more).
Just because the syntax is correct, that of course does not mean that the experiment is well defined. Here are a few possible things you can try:
change the variable list in one or more of the observations that are assimilated. For example, you can remove
eastward_windandnorthward_windfrom the aircraft observations, leaving only temperature (be sure to either include both wind components or not; JEDI-FV3 is currently not configured to handle only one of these wind components).remove one of the observation types entirely, such as aircraft or GNSSRO refractivity measurements.
change the localization length scales for bump (hint:
rhandrvcorrespond to horizonal and vertical length scales respectively).
After each change remember to run the run.bash script again to generate new output.